
Key Points
- There is no need to wait for data to accumulate before leveraging AI and data science to start benefitting from new instrumentation.
- Online algorithms can detect abnormal or novel behaviour, step-changes and trends in data streams from dynamic industrial systems giving early warnings to system owners without needing rich historical data from which to learn.
- Be strategic with system instrumentation to capture the key performance related metrics and contextual information, and store the data in a future proof and easily accessible warehouse enabling the data team.
The constraints that the Covid-19 pandemic has put on the industrial workforce has accelerated an already growing rate of digitisation, with Microsoft reporting 2 years of progress in digital transformation in just 2 months. Increased data collection is often considered a long-term investment, perhaps even alongside ambitious plans for future AI projects. But what about short-term benefits?
In response to Covid-19 and the likely need to implement social distancing for some time, industrial operators are boosting their capacity to monitor and control plants remotely. This enhanced remote monitoring requires installation of new or upgraded sensors thereby presenting an inherent opportunity to implement an enhanced data processing and analysis strategy. However, implementing AI or advanced data science to solve key problems in industrial systems can require large data capture across a full range of operating conditions, and typically take years before a newly implemented sensor provides any value. This inhibits powerful machine learning approaches for:
- Plant parameter optimisation
- Forecast enabled short-term planning
- Predictive maintenance
- Failure classification
- Manufacturing quality control
In this post we find out how newly installed instrumentation can near-immediately support plant operators and allow for data-informed decision making and increased automation.
System learning for anomaly detection
Anomaly detection is a machine learning practice used to detect unexpected or novel observations occurring in our data without having to explicitly learn from past adverse conditions. This enables the automatic identification of problematic system behaviour and to direct protective action. It is particularly useful in systems where failure events are uncommon but of high consequence.
The approach has a range of industrial applications, including:
- Pre-empting the onset of bearing failure in rotating plant
- Measurement of pump degradation to optimise overhauls
- Comparing and ranking the health of multiple parallel systems to prioritise limited maintenance resources
Anomaly detection models can be applied with reduced data requirements compared to large-scale supervised models with the trade-off of having a vaguer output. At Ada Mode we have implemented a self-supervised approach to learn from recent healthy data to build an understanding of normal system behaviour.
Taking inputs from multiple sensors and measurements such as audio, temperature, pressure and vibration, an auto-encoder neural network can be trained to condense and recreate the input to build a fundamental understanding of how the system behaves and how the individual variables interact.
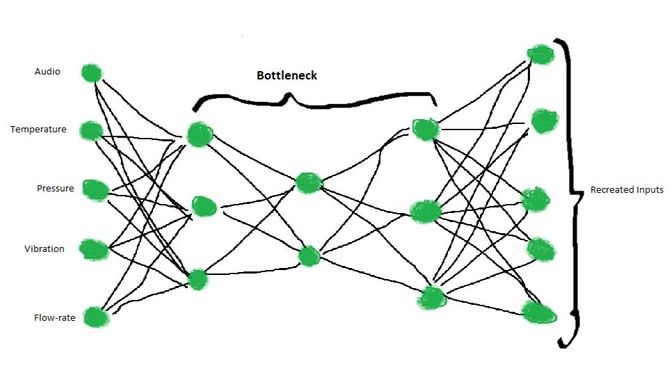
Trained with initial healthy data from new instrumentation, a well-built model of this structure can alert system experts of significant deviations from the expected behaviour based on the recreation score. With this approach, insights could be gained from new plant instruments within a matter of days, allowing for a bedding-in period of the new sensors.
It’s worth noting that dynamic industrial systems often have many different modes of operation, of all of which are normal and expected. In this case it will take more time to build up a robust picture of plant behaviour and may cause some false positive anomaly flags early on, but allowing the model to continuously learn from the data stream under domain expert guidance and building complexity over time will lead to improved results.
At Ada Mode we’ve implemented this approach in a biogas industrial system using just a few weeks of high-resolution sensor data. The model successfully highlights known adverse behaviour in testing with the output becoming more refined as data was continuously gathered.
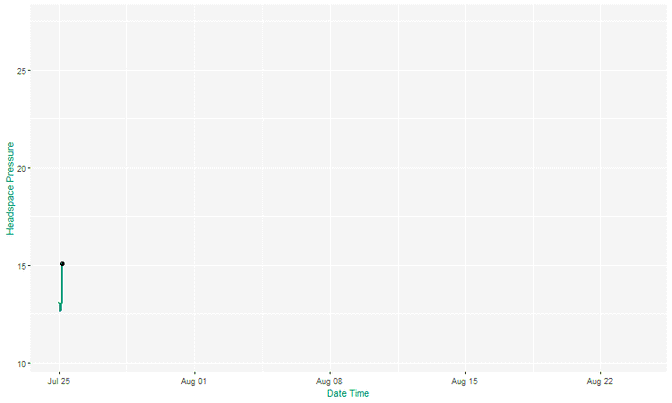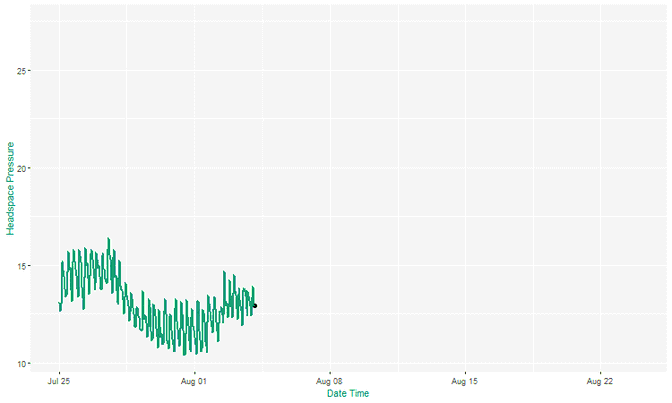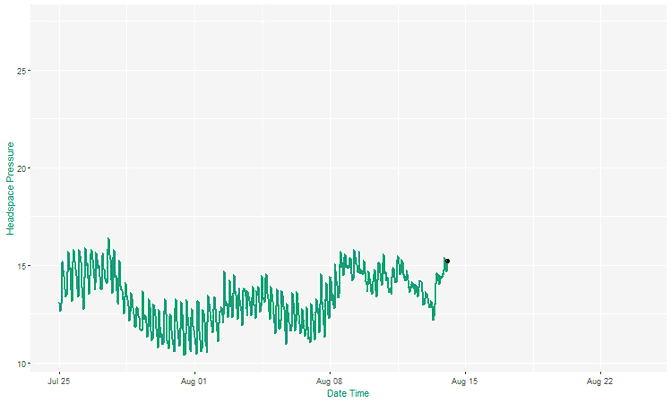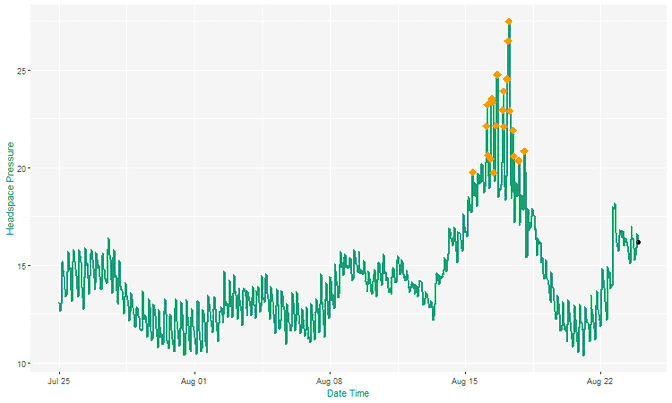
Fall back on the basics to find change
Anomaly detection isn’t the only way to glean insights from new data streams. There is a whole field of online statistical algorithms designed to be deployed on live data, adapt to change and provide continuous insights. Change point detection can detect statistically significant step changes in signal properties, trend monitoring can find and notify of continuous trends of varying lengths and directions. Rule based systems can be developed to automatically check against alarm levels and operating bands as part of an expert system.
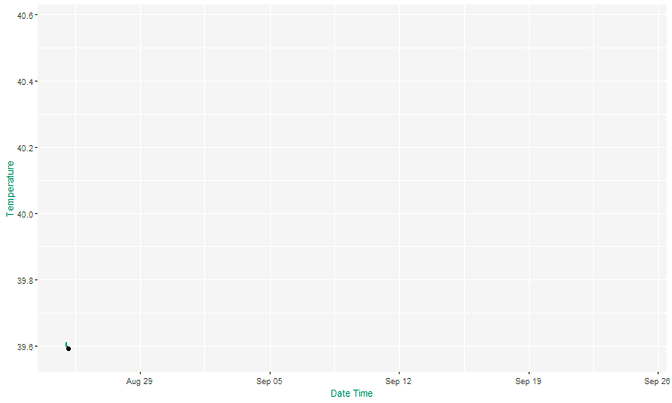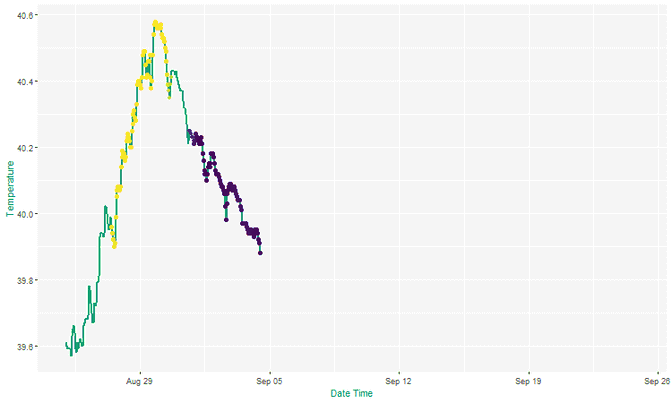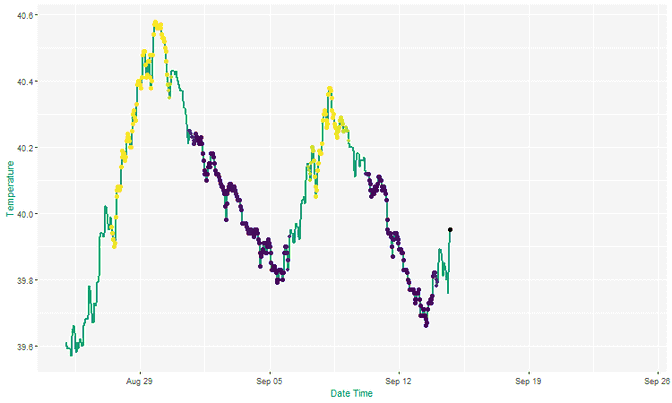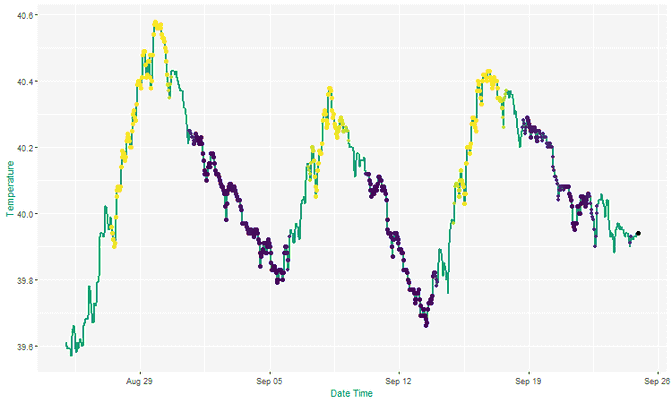
Basic visualisation strategies can have a huge impact in the adoption of data decision making. Interactive and modern dashboarding can allow system owners and engineers to interrogate incoming data with ease, a step away from clunky dated systems.
Building an instrumentation strategy
To optimise the impact of the discussed analysis and more importantly as the big data boom intensifies, it’s crucial that instrumentation is applied with a robust and future proof strategy. At Ada Mode we recommend 3 steps are taken before instrumentation of an industrial system:
- The captured data is comprehensive and on the pulse of system health and performance
- The data stored is easily accessible to those that can extract its value
- Contextual information is accurately collected simultaneously and is easily aligned to the system
By ensuring the breadth of the captured data is sufficient to current and future ambitions it can prevent any regrets down the line about inadequate data requirements and maximise the potential for applying more advanced supervised AI.
By storing data in remotely accessible databases, data scientists, analysts and software engineers can rapidly iterate in development reducing costs and improving the quality of the final product.
Contextual information can consist of recordings such as the target output in manufacturing, plant operating control settings in chemical processes or power output in energy production. This high-level information is key to building up a complete picture when looking back at historical data down the line. The success of AI project can come down to having broad historical context.
Getting these 3 things right will ensure a good chance at thriving in the data revolution for both the short and long term.
Final thoughts
Perhaps digitisation and instrumentation would be even more widely adopted by reducing the lag between large initial investment costs and the returned benefit. The strategies discussed here can deliver that and put data to work from day one.


