
Increasingly over the last year, people have been using the likes of Microsoft’s Copilot and OpenAI’s ChatGPT as their own personal AI Assistants. But how can we build our own projects and apps that utilise the power of an LLM? This article outlines some typical workflows to take advantage of AI in a more bespoke manner for your own projects, harnessing an LLM to act on behalf of your company, giving it domain knowledge and the ability to answer questions relating to your specific business.
The state of LLMs
Large Language Models are making ground breaking strides. It seems like every week there is a new version of a model (or indeed a brand new model) making headlines about how it will revolutionise the space.
The most well known model, ChatGPT, has in recent months released its ChatGPT 4o model, which features multi-modality, allowing not just the standard text input but audio and video, meaning you can talk to it and show it live video, allowing for a more natural conversation.
Lesser known to the wider public (and more interesting to developers) are the improvements to open source models. Mistral released their ‘lightweight’ Mixture of Experts model Mixtral 8x7B which features multiple LLM structures, or “experts”. Each “expert” is responsible for a specific field of knowledge. The mathematics expert can therefore stay dormant when you need help with creative writing, reducing memory usage and making the model more accessible to those with less expensive hardware, whilst maintaining excellent performance.
Other popular models include Qwen2, Google’s Gemma (and their closed source Gemini), and more recently, Meta released their Llama 3 model, which remains one of the more popular open source choices due to its performance in benchmarks.
Casting a broader net, there are dozens more LLMs - hundreds if you include all the forks that community have created, and people are always testing and discovering strengths and weaknesses to each one. It can be difficult to keep up. Every time you go to a model repository like huggingface.co you’ll probably see a new set of trending models. So how do we know where to start?
Are we in an AI bubble?
First and foremost, it’s important to consider whether your project actually needs an LLM. There’s a trend of tech companies (and non-tech companies) shoving AI into products where it doesn’t belong, or where it’s not quite viable yet (see: the Humane AI Pin). There looms a very real danger of the AI bubble “bursting” once the tech giants realise that nobody asked for the things they’re putting so much of their resources into.
Your problems might be better solved with better UI/UX design that intuitively leads users to the information they need, rather than putting hundreds of hours of work into an “AI Assistant” that offers the same info.
But AI does have tangible benefits that could revolutionise industry and the way we work and live. Once you’ve decided that your idea is worthy of an injection of AI, you can decide which structure suits your needs. There are several ways to structure an LLM project.
The simple method – use an API
The simplest way to utilise an LLM in your own project is to use an API, like the one provided by OpenAI to use their models. This gives you access to some of the better performing closed source models such as ChatGPT.
The major benefit here is that you don’t need to worry about hardware and deployment as this is all handled by the API provider. You simply choose a model, and are granted access to it via an API, allowing you to send prompts and receive responses programmatically. You can then build this API into your own bespoke app.
You pay a few cents for every thousand tokens your applications ends to the API. Keep note that you’d usually send the entire conversation history to the API in each prompt, so the number of tokens can add up if you want the AI to remember a longer chat history.
At first glance it seems that this method doesn’t really achieve much over simply visiting the OpenAI website and using ChatGPT normally, but we can customise the LLM.
Firstly, we can build the API into our app, and no one would even need to know it’s actually ChatGPT behind the scenes.
But the more powerful bit of customisation comes with the ability to input a set up prompt. The set up prompt tells the LLM how to format its responses, and you can also input some information to use in its responses.
As an example, let’s pretend we’re setting up a website to sell hiking boots for our company “Boot World” and we want an AI assistant to help answer user questions. In the set up prompt we, as the app developers, could give instruction to the LLM;
“I am a customer and you are a professional shoe salesperson working for the company ‘Boot World’ that sells Hiking footwear. Answer my queries about boots in a professional but friendly and casual manner. Here is a list of products Boot World stocks:
North Ridge Gore-Tex Boot – Pink £85.00
...
Here is a list of physical locations for Boot World:
1059 Broadmead, Bristol, BS1 3EA
...”
This sets up the LLM to respond to all prompts using the given instructions, so it will consistently act as if it’s an employee of our company, Boot World.
As we have passed in data too, the LLM can use these datasets to give more specific answers. The truncated (and fake) dataset above is very simple, but imagine if it held lots of information about each product, such as the sizes that are in stock, whether the boots are waterproof or not. The AI assistant would be fully equipped to answer questions like “What is the cheapest waterproof boot for women that you have?”
We can also add further customisation by sanitising the user’s input prompt before we pass it to the API. Perhaps we could do a quick scan of the user's input prompt to check that they asked a question about shoes. If not, we could then we could reject the message and instead reply to the user with a polite error message.
The advanced method – Fine Tuning an LLM
To develop a truly bespoke LLM, we can train our own LLM using machine learning techniques. This is an enormous undertaking and requires a boatload of data, so it rarely makes sense to start from scratch.
Instead, we can begin by using an open source LLM, pre-trained by companies with far more resources, like the Llama 3 model, trained by Meta. Our model therefore has a solid starting point. It might know multiple languages, and have useful industry knowledge, for example, that “Gore-Tex” products are waterproof.
However, it won’t have information specific to our private company. If we want to teach an LLM to act on behalf of our company, we need relevant data to fine tune the model. The challenge is that the quality of the model is going to be dependent on the quality of your data. And where do we even get this data?
To go back to our example of a website that sells boots, to teach an LLM to effectively answer questions about our brand and products, we would need to finetune the model using a dataset consisting of user queries and the ideal responses. Ideally, we would want thousands, if not tens of thousands of examples, which we probably don’t have.
Perhaps if our company had been running an online chat service using real people for years, we might have this data. But even if we did, we don’t want to train our model on old data, like shoes that our fictional company doesn’t stock any more.
One option is to augment data. We could have our developers manually make up some questions and answers to use for training. This would be time consuming, but if we’re able to write a script that generates thousands of examples then that might be viable... but we need to be careful as real people ask questions in different ways and we need to ensure our training dataset truly represents real world data to create a good model.
But what happens if we introduce new products to the shop? And how would the LLM know about the minute-by-minute changes in stock? Clearly this method isn’t ideal for our scenario.
We can see that fine tuning is more useful for giving an LLM a general understanding of topics, and less useful for giving an LLM up to date live information. If we wanted to teach our LLM about a new scientific field, we could feed it new text books on the subject. But it’s not so useful for our e-commerce chat bot.
Let’s look at some tools that can help.
Vector Databases
Vector databases are fantastic tools to assist LLMs. They use the concept of vectorisation to encode the semantic meaning of a word or collection of words (eg. a sentence or paragraph).Words can be encoded and represented by a vector and stored in a database.
Take the three sentences:
1. The boy ate a red apple
2. The Earth is over 4.5 billion years old
3. I don’t like green bananas
Now imagine we assign 2 parameters, age and colour, to a vector space, with colour on the x-axis and age on the y-axis. We can then plot each sentence in this 2-dimensional space:
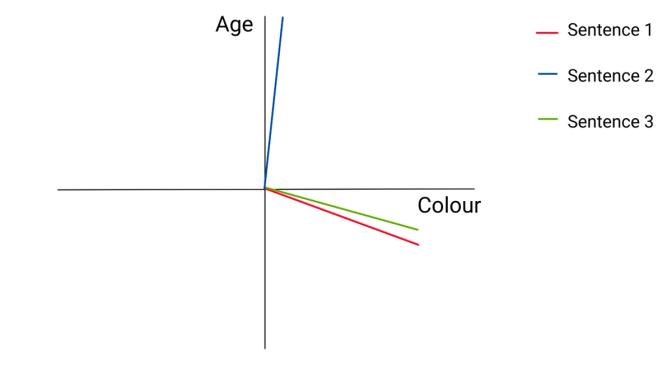
In this vector space, if a word or sentence mentions old age we may see a large y-value towards the top. Referencing youth might see a large negative value for the y-component. And no mention of age at all might have a value around 0.
For sentence 1 and 3,we can see the vectors are similar. The sentences both contain information about colourful fruits (red apples and green bananas), so both have a large x-value for colour. Both also have information about age (the word “boy” implies young, and green bananas imply unripe), but as these are both vague references to age, maybe we’d see a weaker values for the y-component in both these vectors.
The second sentence mentions “4.5 billion years” implying a very large age value, and though the Earth itself might be thought of as a colourful blue-green marble, the sentence itself contains no explicit information about colour, so we might have a low x-value.
This is an oversimplified example; we only have 2 dimensions. In LLMs there may be hundreds of dimensions, with each dimension encoding something different about the semantic meaning of words.
In reality ML algorithms wouldn’t encode with such easy-to-understand parameters like age and colour, but would more likely figure out abstract encodings during the training process, that would be incomprehensible to our human brains.
A vector database allows us to compare a query word (or sentence) to entries in the database, and return entries that are similar. So where do LLMs come into it?
RAG - Retrieval Augmented Generation with Vector Databases
RAG is when you pair an LLM with the ability to retrieve new information, such as from a Vector Database. We can take large documents, break them into smaller chunks and enter those chunks into a vector database.
This vector database can then support our LLM; when the user enters a prompt into an LLM, we can first use their prompt to query our vector database and retrieve some data. Let’s look at an example.
Imagine we have just released a brand-new recipe book, which includes a recipe we invented for a cheesey omelette tortilla wrap. We take all the recipes from our book and enter them into the vector database.
Then we deploy an LLM like Llama 3 to our web app. Our user asks “I want a recipe for a tasty breakfast that uses eggs.” Ordinarily Llama 3 would not know about our new cheesy omelette tortilla wrap recipe from our recipe book since the Llama 3 training set didn’t include our recipe – we only just invented it after all.
But what if we first used this user prompt as a query in our vector database. The process of vectorisation would take the prompt and calculate the semantic meaning of the query by getting its vector. We can then compare this query vector with the recipe vectors in the vector database, and the database should return relevant recipes.
Since our query used the terms “breakfast” and “eggs”, it should find that a cheesy omelette tortilla wrap is semantically similar and return that recipe.
Remember, so far, we haven’t touched the LLM. We’ve just taken the user’s prompt and used that to search the vector database, which returned a recipe.
We can design our app to take the most similar recipes that the vector database pulled for us and add it to the prompt. We saw before with how we could use an “initial set up prompt.” The app we are developing might orchestrate the prompt like this:
“You are a friendly food blogger. Respond to my query using these useful recipes:
Cheesey omelette tortilla wrap:
...
My query: I want a recipe for a tasty breakfast that uses eggs.”
Here we see an initial set up prompt augmented with the recipe we retrieved from the vector database, and finally the user’s query appended to the end. We can now send this to the LLM, and we’d expect it to respond with the recipe from our brand new recipe book.
The incredible thing here is we haven’t had to train a model. We didn’t spend time and money obtaining thousands of data points consisting of questions and answers to train our model. We just gave it the recipe book as part of a vector database.
This offers us a route to solving our earlier question: Given the vast array of existing LLMs, how do we know which model to start with? In this example I mentioned Llama 3, but this structure could easily use any LLM. Since we haven’t had to train it, we can drop in any LLM and see which LLM gives us the best answers.
By being able to quickly test multiple LLMs, we can see which model suits our use case. We could choose the best model per our project requirements; the best performing model, the cheapest API model that returns the desired recipe, or maybe the open source model that uses the fewest resources.
Agents
As LLMs first became popular, people were quick to point out that as language models, they were terrible at maths, (though they have improved since). An agent can pair an LLM’s ability to reason with tools such as calculators or search engines.
Agents work by breaking down a user’s prompt into parts and tackling each part. They follow a loop pattern of Thought > Action > Observation. This gives LLMs the ability to think a bit more like a human, rather than a predictive text generator.
Imagine we ask an LLM:
How has the price of a Freddo chocolate bar changed relative to inflation since the year 2000?
A standard LLM would provide an answer in one response, and I personally had mixed success asking a few different LLMs this question, with them pulling incorrect values for inflation and thinking it was 2022 (or earlier), as that’s when their training data goes up to.
Using agents and pairing it with a calculator and a web search tool, the LLM might process the task a bit more like this:
- Thought: I need to find the price of a Freddo chocolate bar in the year 2000
- Action: Search
- Action input: “Freddo Chocolate bar price in the year 2000”
- Observation: The price of a Freddo was 10p in 2000.
- Thought: I have found the price of a Freddo in the year 2000. Now I need to find out the price of a Freddo chocolate bar today.
- Action: Search
- Action input: “Freddo Chocolate Bar price”
- Observation: The price of a Freddo is 25p.
- Thought: I have the prices of Freddo for 2000 and today. Now I need to find out what inflation was between 2000 and today.
- Action: Search
- Action input: What would goods and services costing 10p in 2000 cost today?
- Observation: Goods or services costing 10p in 2000 would cost 18.42p today.
- Thought: I need to calculate the difference between the price of a Freddo today which is 25p and the price of a Freddo from 2000 with inflation which is 18.42p.
- Action: Calculator
- Action Input: Divide 25 by 18.42
- Observation: 1.357220413
- Thought: I know the final answer. Final Answer: “A Freddo chocolate bar costs 25p. Adjusting for inflation, a Freddo costing 10p in the year 2000 would cost 18.42p today. The price of a Freddo has risen by35.7% relative to 2000, correcting for inflation.”
Under the hood, the agent sets up a flow to use the LLM’s reasoning power to figure out the next step. The LLM can also be asked to format the results as code, for example step 15 might involve asking an LLM to format the action input as JSON which includes an operation from a list of [“addition”, “subtraction”, “multiplication”, “division”] and 2 inputs, and the LLM may return:
{“operation”: “division”, “input1”: 25, “input2”: 18.42}
This format can then be used by a simple python function that we write to perform the calculation, so we are relying on a more robust calculator rather than the LLM’s text generation ability.
We have scratched the surface of agents. Tools like LangGraph and LangChain are the real heroes when it comes to developing an LLM supported by Agents. They are easy to use frameworks that allow you to select an LLM to be the core of your application. From there you can connect extra pieces, such as a vector database or agents to help support the LLM.
Summary
LLMs are powerful tools that can be customised in a variety of ways; from the very quick and simple API integration, taking advantage of set up prompts, to the much more complex deployments which leverage the power of agents and vector databases.
In this way, LLMs can be incorporated into your organisation. To the user, the tool feels like a seamless AI acting on behalf of your business.
The AI space is still evolving as the community figures out new ways tobenefit from the reasoning power of LLMs, and we are excited to see what comes next.


