
Key Points
- Machine reliability problems cause significant and multiplicative availability issues within production lines across the manufacturing industry presenting an opportunity to introduce a predictive maintenance strategy.
- Predictive maintenance can help to prioritise maintenance activity and increase plant availability, but the strategy needs to be carefully considered and implemented.
- The techniques presented here can help increase OA and OEE
Machine Failure is Driving Down Availability
At Ada Mode, we see machine reliability to be a significant driver of unplanned production line downtime. Widespread problems such as calibration faults due sensor drift, tears in production line ribbons and printing inaccuracies are common (> daily) occurrences across many FMCG processes. Although usually only requiring quick fixes, the bulk and volume of small machinery issues such as these will add up over a manufacturing cycle leading to sub optimal Operational Availability (OA), stressed or exhausted maintenance resources and disturbed line staff rotas and rhythms. This problem is amplified in multi-stage, serial manufacturing processes where a single fault can cause a domino effect for downstream sub-processes.
Digital twin technology can enable an improved understanding of the causes of machine failure and the lifespan of various components. Using the human-in-the-loop AI techniques implemented within the digital twin, the operating staff on the line can be better informed of the health of the line in real time. This leads to improved maintenance decision making, increased OA and hence Overall Equipment Effectiveness (OEE).
Understanding Downtime
To start leveraging the benefits of machine learning across a production line within FMCG it is first necessary to robustly track and store downtime data. For each production line, the start and end dates of any downtime event should be recorded over an extended period before considering the application of any more advanced data science techniques.
It is crucial that each of these downtime events is annotated with all relevant contextual information. This should include an informed judgement as to the cause of the downtime event, the action taken by the line team to restart the process, and any engineer comments or clarifications. The collection of suitable contextual information is crucial, it significantly increases the feasibility and scope of all supervised ML applications on the line.
Predictive Maintenance Considerations
There are numerous factors to consider when designing a predictive maintenance solution to alleviate the cost of downtime events.
• What downtime events or categories are avoidable with prior warning?
• Do we have a historic bank of accurately labelled events?
• What of those downtime events have some sort of build-up period or degradation process which may be detectable?
• Is the financial benefit of addressing the downtime event viable?
• What is the impact on OA and OEE?
• What data is required to inform the health analysis of related machinery?
• If you are not already recording the data, what sensor do you need, how/where will you install it, how much historic data do we need to collect before continuing the project?
• Is the data reliable enough to build robust models and generate accurate predictions?
• How performant would a model need to be to provide financial and operational benefit?
• How will operators interact with the model’s predictions and how disruptive will it be to O&M practices; will the production line staff get onboard with alternate maintenance strategies?
• Can the reliability of the process be improved through other, simpler, means?
• Are we targeting the most disruptive problems ensuring a max ROI?
Considering each of these points can be an exhausting process, but each are critical to assess the feasibility of any predictive maintenance ambitions.
The data requirements and problem structure required to implement a supervised machine learning predictive maintenance system can limit its effectiveness. Instead, an unsupervised approach can be used. Anomaly detection techniques can be used to identify unhealthy machine operation prior to any failure onset, allowing for a lot of the same maintenance benefits as the previously described supervised approach.
The Next Step, Machine Learning
The application of machine learning can significantly improve the performance of a manufacturing line. Here we look at several data science and AI approaches that can be used to achieve quick and powerful results.
Remaining Useful Lifetime – RUL Prediction
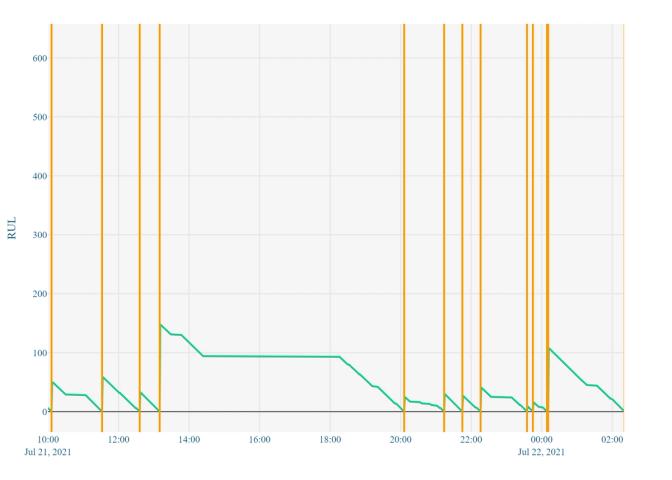
Can we tell operators how many hours of healthy operation a certain component has left on the line? This approach is well suited to gradually developing failure mechanisms; detrimental to the line if complete failure is reached. Clever feature engineering techniques applied to related performance timeseries data combined within a regression pipeline may be able to relate recent operation to historic time-to-failure observations (figure 1).
Such a model would allow operators to optimise their maintenance strategy on the production line informed by an expected failure time. It may allow maintenance to be undertaken earlier, in a preventative manner, at a convenient point in time, such as at the end of a shift or when in a state of downtime due to other problems on the line.
The successful deployment of a RUL model can be difficult, particularly for high frequency downtime sources. The model will likely rely on recent historic failures to engineer required features. Hence it is essential that an efficient downtime reporting platform is in place and a data driven culture exists amongst the O&M staff to drive the near-real time documentation of incoming downtime events.
Training accurate RUL models is often difficult. The distribution in component lifetimes is often highly variable, as seen in figure 1. If this wasn’t the case, then RUL would always be known. It is the purpose of the ML approach to identify features in the data which are driving the variable lifespans and using that information to produce an informed view of RUL. However, for a freshly installed/maintained component, there is very little component data to go by and hence the initial RUL predictions will be subject to high uncertainty.
It’s worth noting that this is not the only way of framing a solution to RUL prediction. Other methods may be attempted such as survival analysis or threshold forecasting.
Faulty Operation Classification
Some downtime sources are the result of more rapid/spontaneous failure mechanisms. These downtime events are not suited to an RUL approach, due to the near binary nature of the of failure onset. However, some operating modes may be more susceptible to complete component failure and hence involve an increased risk.
By identifying when operation is at elevated risk of impending failure, precautions can be taken such as reducing throughput. This increased level of awareness enables O&M staff to direct the process in an optimal way so performance can be maximised under a tolerable level of component risk.
Calibration Drift Detection
It is common across FMCG for instrument calibration drift to be a frequent cause of downtime. This may affect processes causing over/under filling of packages, misaligned or misplaced parts, faulty printing or labeling or other quality events. To maximise quality, and hence OEE, it is necessary to carry out frequent calibration checks and adjustments. However, this scheduled maintenance burden leads to increased downtime, reducing availability, and hence OEE. A balance must be found.
Ada-Mode’s sensor drift detection methodology can be applied here to provide an informed view into instrument calibration. This is achieved through the development of AI enabled soft-sensors, acting as a digital twin of the observed instrumentation. By comparing the observed instrumentation readings against that of the digital twin, calibration drift can be detected. For more information on sensor drift click here.
Such an approach can allow for the detection or early warning of instrument drift which could allow for remediation before a significant hit to production quality or subsequent instrument failure. While simultaneously allowing for instantaneous calibration checks without the need for manual inspection.
Summary
Here we have presented a number of approaches to implement predictive maintenance within FMCG and manufacturing production lines. Alongside some of the pre-requisite infrastructural requirements and planning considerations needed before developing such a platform.
The design of the predictive maintenance solution is heavily dependent on the nature of the target failure mechanism. Such methods include RUL prediction, survival analysis, threshold forecasting, failure classification and anomaly detection.
Before any predictive maintenance solutions can be robustly developed it is crucial to develop a downtime reporting platform to capture and label sources of downtime. Forming the failure labels used within supervised machine learning approaches.


