
Key Points
Machine Learning can be used to expedite complex engineering design processes to reduce cost and development time
Data from computational simulations can be used to train surrogate models
Surrogate models enable rapid iteration through the design space to find optimal parameters to finalise a design
Leverage data science techniques to guide and plan design experiment cycles, reducing design costs and improving the overall outcome
Can Machine Learning Enable a Step-Change in Engineering Design?
The design phase of any industrial project has become increasingly important as technology and infrastructure becomes more complex and interdependent. The process is often complex, expensive and time-consuming, requiring the construction of experiments, prototypes or computational simulations alongside finalisation of the design space.
Increasing computational power has enabled an upturn in the volume of computer-aided design implemented across industry. This, in turn, enables improvements infields such as aerodynamics, fluid dynamics, building information modelling and energy modelling. But simulations are not constructed as optimisation tools.They allow for a trial of a design but not a robust exploration of a design space hence the discovery of optimal and robust designs is often a sticking point. Some simulations are very expensive to complete, causing a trial and improvement approach to be slow and inefficient. Advances in computational performance are leading to more complex simulations rather than faster iterations only amplifying the problem.
Here we explore if machine learning can enable the next step-change in engineering design efficiency and optimisation.
Simulation & Surrogate Modelling
Using a simulation of the proposed design performance, AI algorithms can help to finalise the design through an optimised exploration of a design space. From a sparse set of feasible designs and their corresponding performance outcomes,recorded via simulation, machine learning surrogate models may be trained to understand the relationship between design variables and aspects of performance.
The surrogate models can then be used to further explore the design space in place of the simulation. The predictive surrogate model can assess designs many times faster than any computational model. As a benefit of the improved assessment speed,optimisation techniques can be applied to a multi-objective design problem to find near-optimal solutions.
A key step in the surrogate modelling process is ensuring that the surrogate models are suitably accurate to the simulation. As the surrogate model is a double abstract of any real process, it is possible to compound errors or inaccuracies already present in a simulation.
Optimised Engineering Design on a Limited Budget
In some applications, it may not be feasible to run a suitable number of initial simulations to enable the development of the surrogate model(s). This is likely due to extreme simulation complexity and/or a limited design budget. In such cases, it is critical that the design budget is used economically to ensure the design space is explored as efficiently as possible given the limited resources.
In such cases, it is recommended to use the same principles of the surrogate model approach but instead applied iteratively in between experiment runs. Typically, this is done with Gaussian process models and Bayesian optimisation. This approach helps guide operators to carry out simulation iterations within the most promising regions of the design space, and hence preventing wasteful or non-informative experiments.
Using Bayesian optimisation in this way is regarded as a best practice for the optimisation of expensive functions such as those often seen in simulation. The methodology enables efficient exploration of the feasible design region in the search for optimality.
This can provide significant benefits to industry. The cost and time implications of iterating through the design space in a traditional manual approach can be severe. By completing a thorough and intelligent review of the data recorded from each experiment before deciding on the next steps, these costs can be reduced while reaching improved design effectiveness.
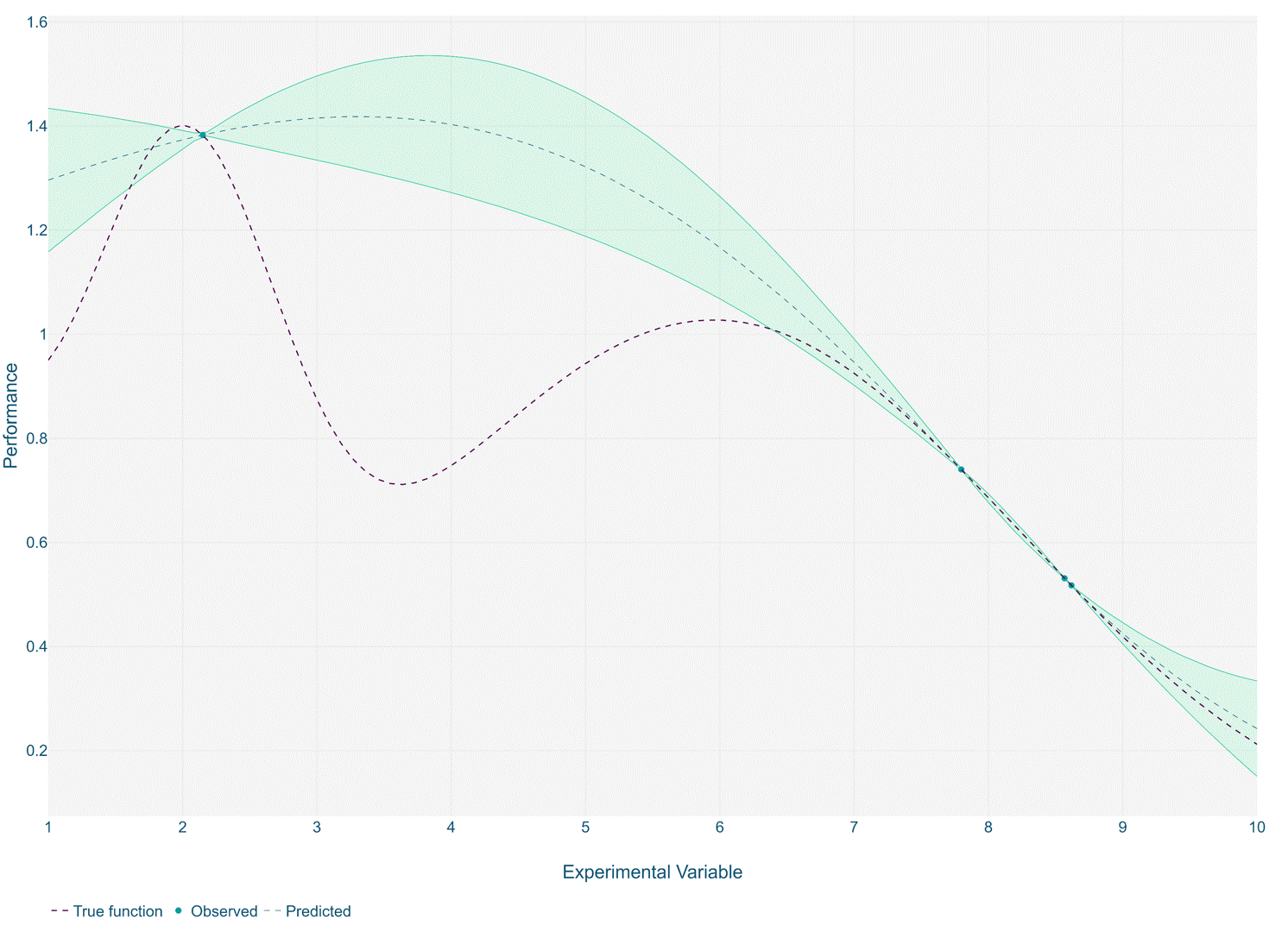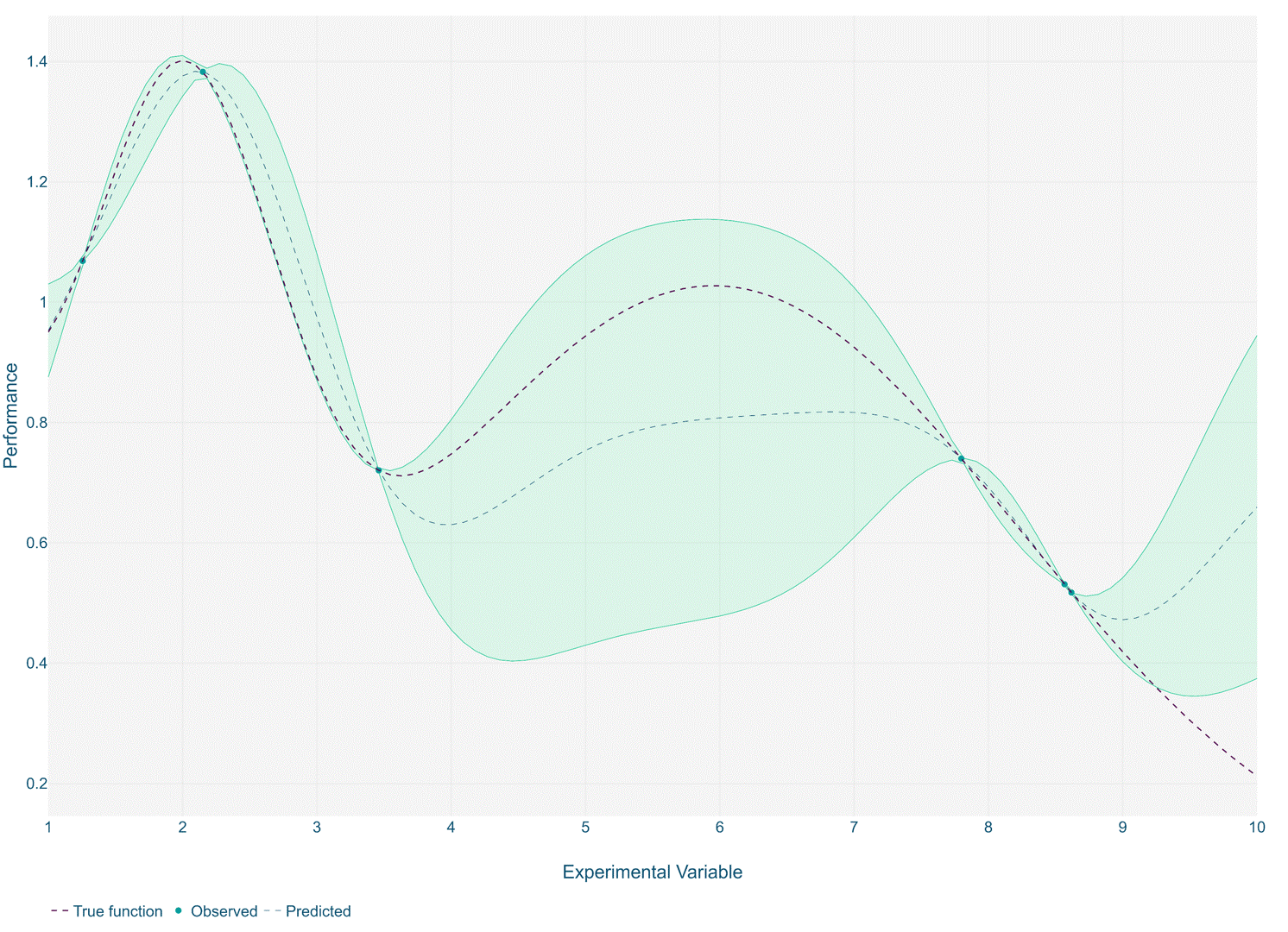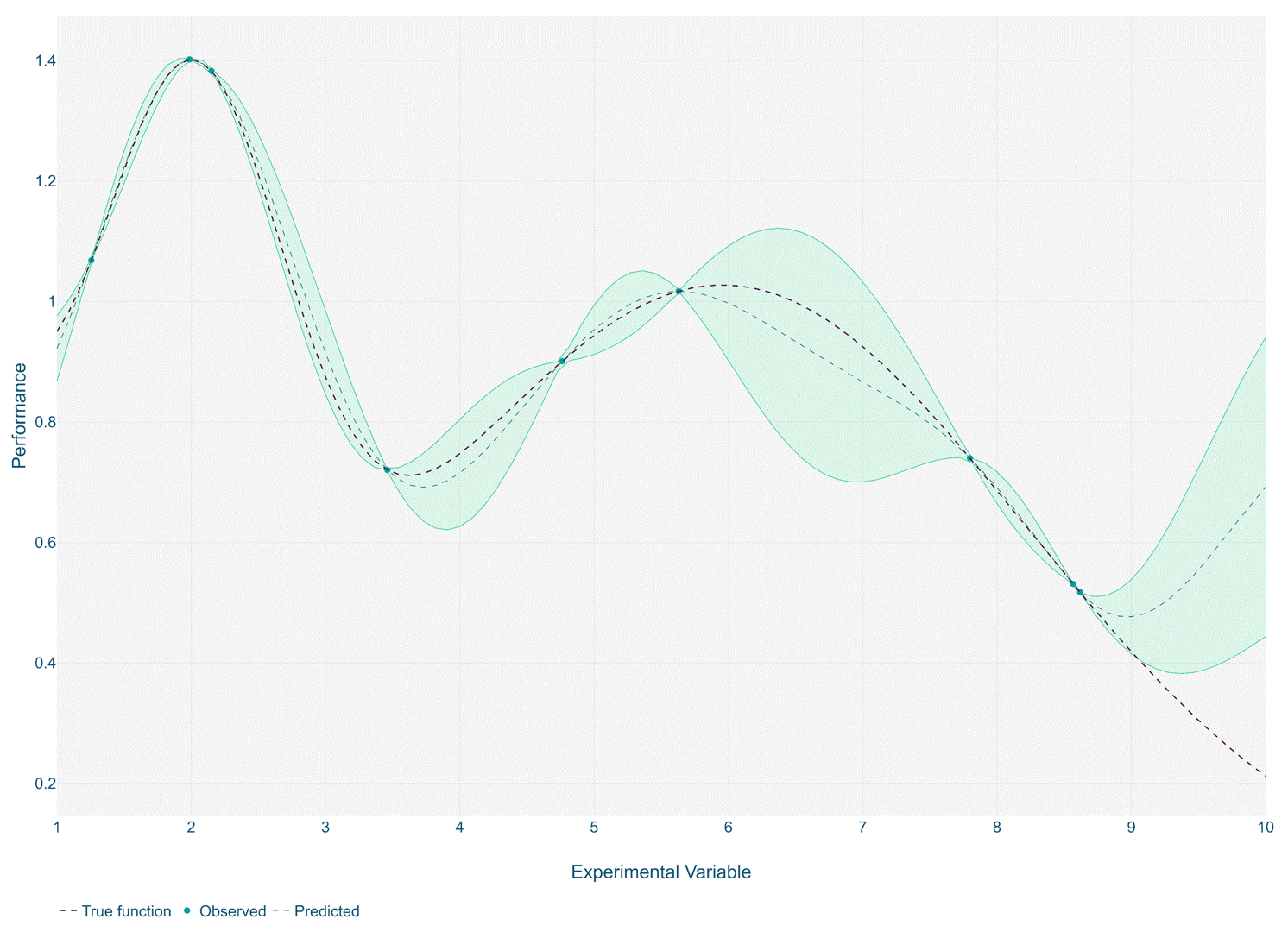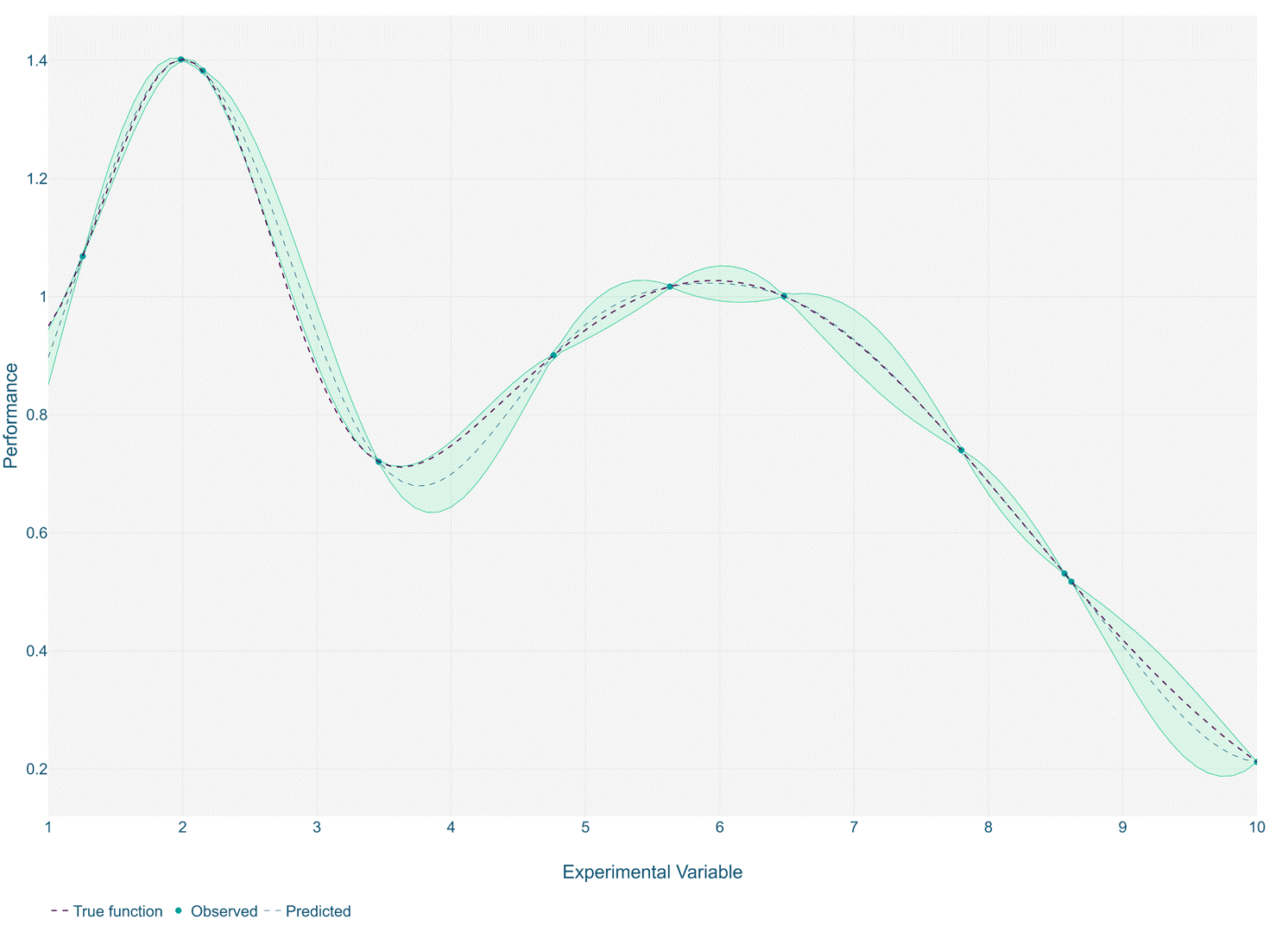
The optimisation process works by training a gaussian process model over a small number of initial experiments. A subsequent experiment is recommended, that is expected to find a new optimal solution based on the trained Gaussian process. This can be repeated iteratively until a stable solution is reached or the experiment budget is exhausted.
Application to Chemical Dosing Campaigns
The UK’s nuclear operator, EDF Energy, identified a need to perform a chemical cleaning campaign on a critical plant. The objective of this clean was to return the plant to the design state while minimising any risks and impacts which may arise from the campaign.
A discrete event simulation method was developed to track how the clean would progress and help to inform decisions on where to fix certain key variables.
A deep review of the design space was required at a high resolution in order to find and understand the factors that lead to performant solutions. The time and computational complexity of the simulation prohibited this at the required scale. Therefore, a machine learning surrogate model of the simulation was developed.
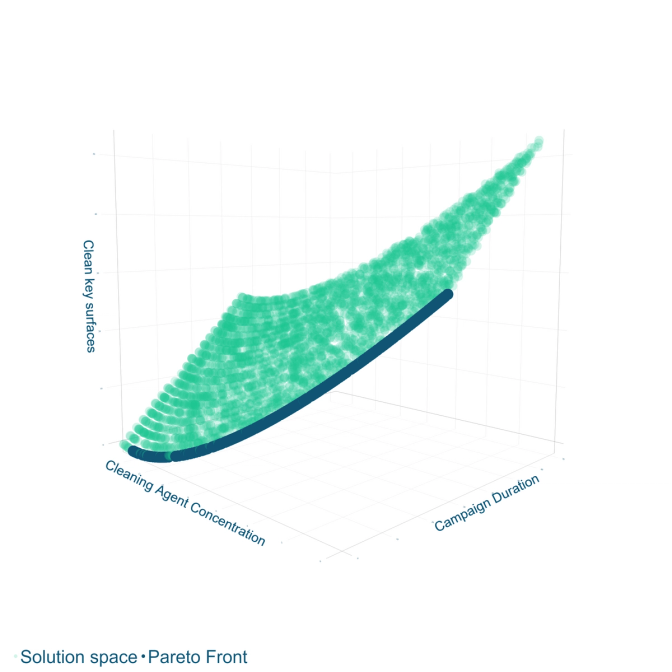
The data returned from a set of ~3500 simulation campaign trials was used to train several surrogate models. Each surrogate was trained to predict a different dimension of the campaign’s performance. The surrogate enabled large speed increases. It took ~8 hours to complete the 3500 initial simulations, the surrogate was able to assess the same number of designs in < 1 second to a high level of accuracy.
This rapid ability to assess candidate designs enabled the application of multi-dimensional genetic algorithm optimisation techniques. This led to the identification of the Pareto front, a set of the design space that has shown to be dominant solutions in varying dimensions of performance. A solution from this optimal set can then be selected by considering the practical implications of each solution and the utility of the decision-maker.
Conclusion
In the traditional simulation approach, expert judgements are used to constrain which parameters to vary, which experiments to run, and which sensitivity analyses to carry out. By enabling major improvements in design assessment speed, machine learning surrogate models remove the need for such selection and support decision-makers throughout the design process as a digital twin.
The use of such a machine learning approach is especially powerful for complex multidimensional problems where traditional simulations are computationally expensive and/or subject to extensive constraints in order to make implementation feasible.
Here we have presented just one area suitable for the application of surrogate modelling using machine learning but with increased levels of computational modelling across industry, the possible applications are far wider. Some examples include:
Design processes to meet enforced regulations related to emissions and waste. Minimise the risk of incurring imposed sanctions such as carbon penalties or maximise return from government incentives.
Other chemical dosing schemes common within the water and bio-waste industries, such as the application of anti-foaming agents within anaerobic digestion tanks.
Environmental considerations such as optimal heating and energy consumption within building design. Reduce unnecessary expenditure on heating/cooling of larger buildings.
Design and manufacture of a consistent product meeting customer expectations by optimising quality in the manufacturing process for FMCG.
Take a look a tour machine learning surrogate modelling case study here for more information
Or to find out about how machine learning can help your organisation please get in touch


